算力平台解决方案
1. 项目背景
作为AI市场中的重要组成,以GPU、FPGA等为主的AI加速器是AI应用发展的最基础资源。GPU成本高昂,传统的GPU调度方式面临着资源利用率低、隔离性差等挑战;伴随AI大模型的广泛发展,对GPU虚拟化、池化调度能力提出更高技术要求。企业在实际应用人工智能的过程中仍然面临AI算力、算法及数据等方面的阻碍:
l 在AI算力方面,企业的IT基础设施在云原生和分布式架构的条件下可能面临的算力分配难以及异构算力问题,使得企业AI应用的可用性下降。
l 在算法领域,以“大模型”为代表的人工智能算法模型体现出模型参数的数量不断增加的趋势,高度复杂化的模型融入应用程序后可能带来应用延迟的增加,而在交付和部署后对模型的频繁更新也会给工作带来新的挑战。
l 由于训练/测试环境和生产环境存在差异,实际应用中的数据存在传输、共享、协作、安全等一系列问题。
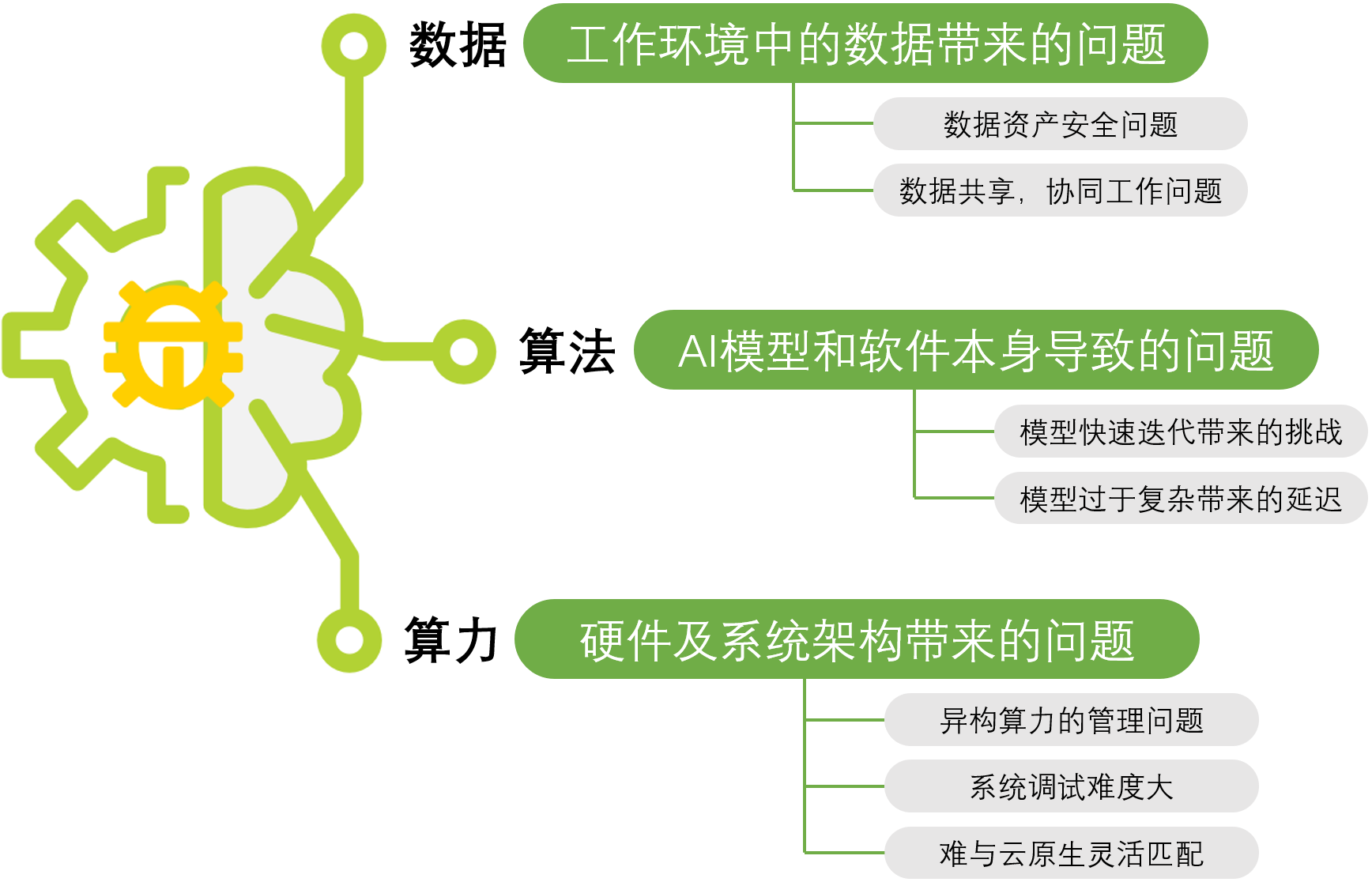
如何对应解决以上问题,提供面向AI生命周期,敏捷云原生,集群智算资源高效利用的AI PaaS平台,成为很大的挑战。
2. 方案概述
软件定义AI算力平台,以分层的方式,在IAAS层对应解决底层GPU算力池化,以及在PaaS层面向终端用户提供简便易用AI开发训练推理部署平台,为企业客户使用AI算力提供高效便捷的解决方案。
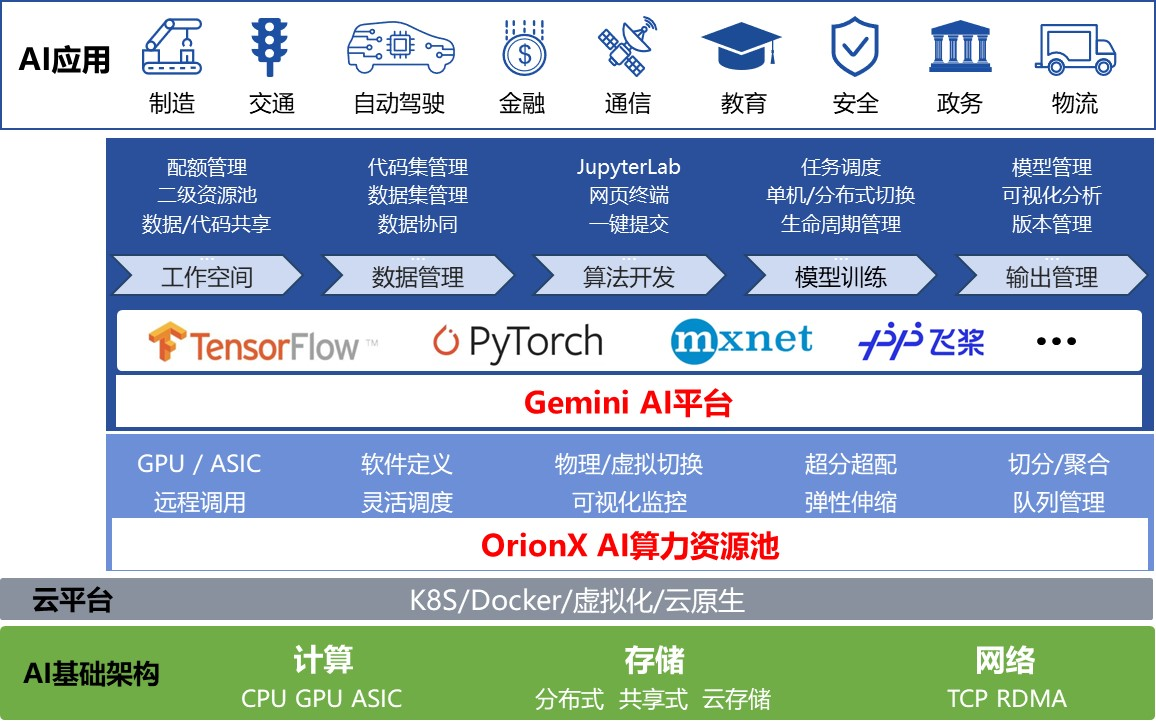
2.1. GPU池化平台OrionX
OrionX帮助客户构建数据中心级AI算力资源池,使用户应用无需修改就能透明地共享和使用数据中心内任何服务器之上的AI加速器。OrionX不但能够帮助用户提高AI算力资源利用率,而且可以极大便利用户AI应用的部署。
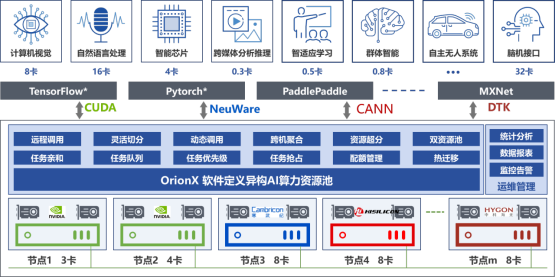
OrionX通过软件定义AI算力,颠覆了原有的AI应用直接调用物理GPU的架构,增加软件层,将AI应用与物理GPU解耦合。AI应用调用逻辑的vGPU,再由OrionX将vGPU需求匹配到具体的物理GPU。OrionX架构实现了GPU资源池化,让用户高效、智能、灵活地使用GPU资源,达到了降本增效的目的:
· 提高利用率
支持将GPU切片为任意大小的vGPU,从而允许多AI负载并行运行,提高物理GPU利用率。
提高GPU综合利用率多达3-10倍,1张卡相当于起到N张卡的效果,真正做到昂贵算力平民化。
· 高性能
相比于物理GPU,OrionX本地vGPU性能损耗几乎为零,远程vGPU性能损耗小于2%。
vGPU资源隔离,并行用户无资源互扰。
· 轻松弹性扩展
支持从单台到整个数据中心GPU服务器纳管,轻松实现GPU资源池的横向扩展。
全分布式部署,通过RDMA(IB/RoCE)或TCP/IP网络连接各个节点,实现资源池弹性扩展。
· 灵活调度
支持AI负载与GPU资源分离部署,更加高效合理地使用GPU资源。
CPU与GPU资源解耦合,两种服务器分开购买、按需升级、灵活调度,有助于最大化数据中心基础设施价值。
· 全局管理
提供GPU资源管理调度策略。
GPU全局资源池性能监控,为运维人员提供直观的资源利用率等信息。
· 对AI开发人员友好
一键解决AI开发人员面临的训练模型中GPU/CPU配比和多机多卡模型拆分问题,为算法工程师节省大量宝贵时间。
2.2. AI一体化平台Gemini
Gemini AI平台,针对模型开发训练场景,整合算法、算力、数据,构建一体化平台,提供强大的AI资源管理服务以及高效的算法开发和训练支持,能够提高开发人员的工作效率,缩短开发周期,帮助企业建好AI平台、管好AI资源、用好AI服务。通过该平台:
提升资源利用效率
l 支持系统资源超分,用户越多,整体资源利用率就越均衡。
l 原生支持GPU虚拟化,极限利用每一张GPU的算力。
l 超量任务进入队列,不浪费GPU等待时间。
提高算法工程师工作效率
l 数据、镜像、代码集中管理,便于算法工程师查看和使用。
l 整合的开发和训练环境,算法工程师可以集中精力于业务本身,无须过多关心环境配置问题。
l 开发环境中可一键提交训练任务,衔接顺畅。
l 友好的分布式任务支持,帮助算法工程师成功启动分布式训练,缩短训练时间。
l 友好的推理部署模块,支持一键部署,按需扩缩容等。
l 支持团队工作,交流与共享数据。
降低运维管理难度
l AI 原生的运维管理,简化 GPU 资源管理,提高运维管理人员的管理效率。
l 细粒度权限控制,适应不同企业的管理需求。
l 数据管理权限可以单独分配,降低运维对于数据资产管理的难度。
l 支持团队自主管理,降低运维管理中心化压力。
3. 系统部署方案
3.1. OrionX部署
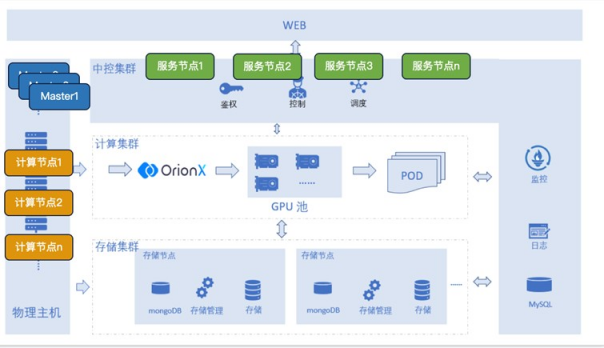
采用OrionX与Kubernetes集成的部署方案,部署架构见下图。
OrionX为Kubernetes对接提供两个插件,实现与K8S的集成对接。集成后,系统管理员只需要在K8S中,即可完成对GPU资源池中vGPU资源的配置和调度管理。并且,允许系统管理员通过单一接口调度全部数据中心资源,实现SDDC(Software Defined Data Center,软件定义的数据中心),这样就简化了运维工作。
部署组件包括:
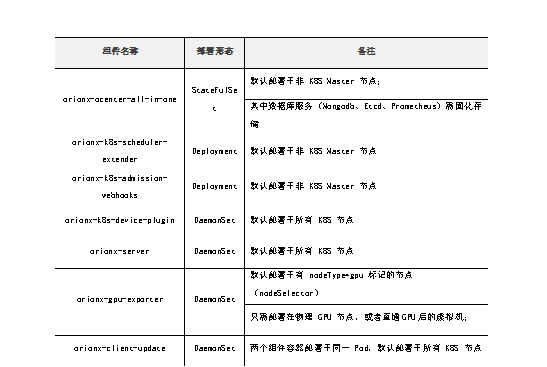
3.2. Gemini部署
Gemini部署在K8S和OrionX之上,通过和K8S/OrionX的集成,在Gemini平台上以容器方式申请调度使用底层的通算/智算资源,并集成NFS以提供Gemini平台上的数据资产的保存。
3.3.
平台资源需求
本次项目涉及池化2台H20 8卡服务器,2台8卡V100服务器以及2台4卡V100服务器,平台两套软件OrionX和Gemini可采用单节点非冗余的部署方式,并通过NFS接口集成已有的Ocean Stor Pacific 9920或EMC Isilon A200 NAS存储用以保存Gemini平台上的AI数据资产(数据集,代码级,镜像,模型文件等)。
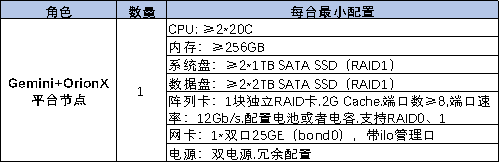
平台安装所需CPU服务器配置要求如下:
4. 方案优势
本方案在 GPU 池化领域拥有深厚的技术积累和持续的创新能力,在资源分配、算力管理、技术架构等多个方面都具有显著的创新优势,能够为企业提供高效、灵活、稳定的计算资源管理解决方案,采用了多项先进的技术理念和算法。
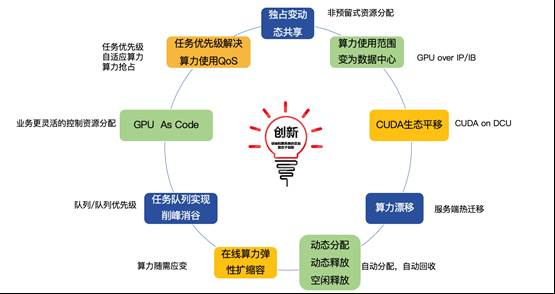
基于最核心的算力和应用解耦为基础,本方案不但能实现最基本的物效提升,而且能够提升运维中业务的连续性,提高算力弹性和动态灵活使用水平,增强业务高可靠性。这才是真正全面从客户的视角提升智算集群的算力赋能,实现综合价值最大化。 |

